Previous posts in this blog have discussed the use of HTTP for direct operations with the DBMS. With Pyrrho's support for RESTViews it becomes very important to have REST interfaces to other DBMS, and there are several products such as dreamfactory and restifydb that offer this.
From today the Pyrrho distribution includes a very simple solution for MySQL, called RestIfD , and controllers to support other DBMS will probably be added over time. There is a GitHub repository for Restif at https://github.com/MalcolmCrowe/Restif .
RestIfD should be started up by an administrator on the same host as the MySQL instance, and left running. It requires no configuration, creates no files and uses very little memory. It provides a REST service on http://localhost:8803/REST/MySQL , and all requests should include an Authentication header giving the user and password for accessing MySQL.
To obtain a list of databases in Json format, use GET to http://localhost:8803/REST/MySQL . To send one or more commands to MySQL, place them in posted data to POST http://localhost:8803/REST/MySQL .
To obtain a list of tables on database db in Json format, use GET to http://localhost:8803/REST/MySQL/db .To send one or more commands for database db to MySQL, place them in posted data to POST http://localhost:8803/REST/MySQL/db .The group of commands is executed in a single transaction.
To obtain the rows of table tb on database db, in Json format, use GET to http://localhost:8803/REST/MySQL/db/tb .
To filter these results using a where condition or document w, use GET to http://localhost:8803/REST/MySQL/db/tb/w . You can delete rows from the table by using a DELETE requests to a similar url.
To update a single row in table tb on database db, send it in Json format as posted data to POST http://localhost:8803/REST/MySQL/db/tb . The row to be updated will be identified by the key fields in the supplied data.
To add a single row to table tb in database db, send it in Json format as posted data to POST http://localhost:8803/REST/MySQL/db/tb .
Comments welcome.
Friday 9 June 2017
Saturday 3 June 2017
Pyrrho Version 6.0
The new version completes some of the changes announced in previous posts in this blog.
Workarounds for users incovenienced in this way include continuing to use v5.7 for now, manually to strip the last 5 bytes from the binary file, or rebuild v6's OSPSvr without the APPEND flag. But see the next point.
v.6 OSPSvr by default doesn't support the Distributed and Partitioned features either but again these can be restored by removing the LOCAL build flag. The Pro version by default continues to use the end-of-file tamper-proof lock and distributed/partitioned features. These have been enhanced as described below.
A: Open Source Version and Append Storage
Append storage has been a build option for some time in Pyrrho, and the new version uses it by default for the Open Source version. Unfortunately this means that databases built with the previous default version of OSPSvr (up to 5.7) cannot be used with the new default build (v.6) because they won't have the encrypted end-of-file marker.Workarounds for users incovenienced in this way include continuing to use v5.7 for now, manually to strip the last 5 bytes from the binary file, or rebuild v6's OSPSvr without the APPEND flag. But see the next point.
v.6 OSPSvr by default doesn't support the Distributed and Partitioned features either but again these can be restored by removing the LOCAL build flag. The Pro version by default continues to use the end-of-file tamper-proof lock and distributed/partitioned features. These have been enhanced as described below.
B: Using the latest version of C#
The codebase uses the 2017 version of C# with its shortcut implicit declarations e.g. if (x is SomeClass y), and .NET's clever new Task model for some purposes, including for Push, described next.C: Push and Pull for update notifications
Distributed and Partitioned operation up to v 5.5 was not very scalable as transaction masters and base partitions were contacted at the start of every transaction by every replica and partition to check that the local copies were up to date. Some versions since v.5.5 have contained bugs in this area. This is now remedied in v6.0 with the following interesting design, visible in the Open Source codebase and used in the default PyrrhoSvr build.
From v6.0 servers holding slave databases and partitions check their copy information is up-to-date only on start-up, and thereafter receive Push notifications about any changes to database length. They will retrieve the details of the changes when and if they need to. This mechanism works in a hierarchical way so that the Push load is shared by intermmediate servers if these have been configured. All this did complicate the implementation, since server-server communication channels need to be between threads, but it is worthwhile for theoretical reasons.
I will update the screenshots and documentation in the distributed and partitioned tutorials in the next days.
D: Enhancements to the HTTP/REST services
Previous posts in this blog have referred to ETags and RESTViews. A paper on these has now been published, thanks to Friz Laux, Mart Laiho and Carolyn Begg. The practical effect of these features could be adopted much more widely than Pyrrho, and I hope to return to this aspect soon.
Basically, it would be great if all DBMS provided a really simple REST service so that a simple GET would get a table (or other query results) in Json format together with an RFC7232 ETag. Even better if such a view was also potentially updatable with PUT, POST and DELETE. If this is done, database applications can always use WebRequests instead of the clunky APIs: JDBC,ODBC, ADO.NET, JPA.... The authorisation arrangements for this should also be simple and preferably role based, and use the If-Match HTTP header to check ETags.
This works already for Pyrrho (If-Match from v6), and there is more:
HTTP is stateless so the simple steps described above don't provide a way of making several changes in a single HTTP call. But at least for a single database, ACID transactions can be supported by a simple POST of an SQL statement to the database (+role) URL, since SQL statements can be compound and have exception handlers etc. And the POST can be guarded by If-Match to if the SQL statement contains data previously obtained from the database.
It is definitely a step too far in my opinion to try to use these mechanisms for transactions that change more than one database.
As usual, any comments welcome, preferably to malcolm.crowe at uws.ac.uk (make sure the subject line of the email is relevant).
Thursday 6 April 2017
Anonymous row types and monotonic functions
A previous blog post explained about the usefulness of mutually inverse function pairs. It is also useful to know if a function is monotonic. Many joins can be speeded up if the join condition uses a function that is known to be monotonic, so that the table operands are then automatically sorted before forming the join.
Most CASTs are monotonic, and Pyrrho now allows a user-defined function to be declared MONOTONIC through the use of metadata.
For example
create function f(b date) returns (int,int) monotonic return (extract(year from b),extract(month from b))
This function could be used to help join a table with a date primary key to one with a primary key containing year and month, using a join condition such as WHERE (y,m)=f(b) .
In this example we also two small innovations in the current version, as (a) the return type of the function is an anonymous row type, (b) no real distinction is made in Pyrrho now between ON conditions in inner joins, and WHERE conditions in cross joins.
In recent versions of the SQL standard ON conditions can be any boolean expression, so by default Pyrrho combines them and decides which is faster, and whether an index can be used to speed things up.
Most CASTs are monotonic, and Pyrrho now allows a user-defined function to be declared MONOTONIC through the use of metadata.
For example
create function f(b date) returns (int,int) monotonic return (extract(year from b),extract(month from b))
This function could be used to help join a table with a date primary key to one with a primary key containing year and month, using a join condition such as WHERE (y,m)=f(b) .
In this example we also two small innovations in the current version, as (a) the return type of the function is an anonymous row type, (b) no real distinction is made in Pyrrho now between ON conditions in inner joins, and WHERE conditions in cross joins.
In recent versions of the SQL standard ON conditions can be any boolean expression, so by default Pyrrho combines them and decides which is faster, and whether an index can be used to speed things up.
Friday 31 March 2017
Adapter functions, updatable views and joins
With the introduction of REST Views it has become more interesting to support updatable views and joins, and more important to support adapter functions. The Beta version 5.7 of Pyrrho makes some important contributions in these aspects.
In the following sample, we model a situation where databases have columns that nearly match but do not quite do so. For example suppose Table A(B,C) has an integer primary key B, while table D(E,G) uses corresponding string values all prefixed by the letter H as its primary key E. It is easy to define a suitable adapter function F
create function f(x int) returns char return 'H'|| cast(x as char)
and create a view of A that makes sense in D's database:
create view v as select f(b) as fb,c from a
D, however, wishes to be able to update table A, so would like this view to be updatable. Pyrrho allows the declaration of an inverse of F:
create function f1(a char) returns int inverts f return cast(substring(a from 1) as int)
where the phrase "inverts f" is parsed as metadata for the new function f1 (otherwise everything so far is ordinary standard SQL). This makes f and f1 into mutually inverse functions, that is, declaring f1 as an inverse for f also declares f as an inverse of f1. The machinery works for multiple parameters using row types for the return values.
This makes v updatable and we can write
insert into v values('H91','This is new')
We can also use such adapter functions in referential constraints, e.g. a slight extension to SQL in Pyrrho allows us to declare the above relationship between tables A and D as follows:
create table d (e char references a using f1,g int)
The following SQL sample code demonstrating the above ideas is supported by Pyrrho 5.7 as of today.
create function f(x int) returns char return 'H'|| cast(x as char)
[create function f1(a char) returns int inverts f return cast(substring(a from 1) as int)]
select f(45) from static
select f1('B67') from static
create table a(b int primary key,c char)
insert into a values(23,'Twenty3'),(42,'Forty2')
create view v as select f(b) as fb,c from a
select * from v
insert into v values('H91','This is new')
table a
create table d (e char references a using f1,g int)
insert into d values('H23',234),('H91',567)
create view w as select c,e from a left join d on b=f1(e)
delete from w where c='Twenty3'
table a
In the following sample, we model a situation where databases have columns that nearly match but do not quite do so. For example suppose Table A(B,C) has an integer primary key B, while table D(E,G) uses corresponding string values all prefixed by the letter H as its primary key E. It is easy to define a suitable adapter function F
create function f(x int) returns char return 'H'|| cast(x as char)
and create a view of A that makes sense in D's database:
create view v as select f(b) as fb,c from a
D, however, wishes to be able to update table A, so would like this view to be updatable. Pyrrho allows the declaration of an inverse of F:
create function f1(a char) returns int inverts f return cast(substring(a from 1) as int)
where the phrase "inverts f" is parsed as metadata for the new function f1 (otherwise everything so far is ordinary standard SQL). This makes f and f1 into mutually inverse functions, that is, declaring f1 as an inverse for f also declares f as an inverse of f1. The machinery works for multiple parameters using row types for the return values.
This makes v updatable and we can write
insert into v values('H91','This is new')
We can also use such adapter functions in referential constraints, e.g. a slight extension to SQL in Pyrrho allows us to declare the above relationship between tables A and D as follows:
create table d (e char references a using f1,g int)
The following SQL sample code demonstrating the above ideas is supported by Pyrrho 5.7 as of today.
create function f(x int) returns char return 'H'|| cast(x as char)
[create function f1(a char) returns int inverts f return cast(substring(a from 1) as int)]
select f(45) from static
select f1('B67') from static
create table a(b int primary key,c char)
insert into a values(23,'Twenty3'),(42,'Forty2')
create view v as select f(b) as fb,c from a
select * from v
insert into v values('H91','This is new')
table a
create table d (e char references a using f1,g int)
insert into d values('H23',234),('H91',567)
create view w as select c,e from a left join d on b=f1(e)
delete from w where c='Twenty3'
table a
Friday 17 March 2017
Composite Database example with details
This post gives more details of the example contained in the posting Composite Databases in this blog.
insert into D values (1,'Joe','Soap'), (2,'Betty','Boop')
Database B:
'http://localhost:8180/A/A/D']
create view V as select * from W natural join H
The square brackets here are added because of the embedded newline added in the formatting of the page.
After setting up the databases on A and B with B’s views defined, we see the transaction log contents for A and B. Some of the numbers shown will be used in RVV and ETags in what follows.

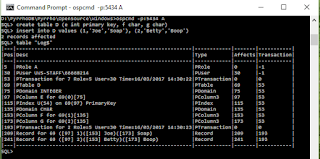









This time the readCheck information indicates it will conflict with any read operation on table 69.



The following transcripts use the beta version 5.7 of Pyrrho
dated 16 March 2017, and using localhost instead of servA, with servers A and B
using folders \A and \B respectively. I have set a debugging –D flag on server
A so that that we can see the use of RVVs and ETags.
We begin by setting up the databases on servers A and B:
Database A:
create table D (e int
primary key, f char, g char)insert into D values (1,'Joe','Soap'), (2,'Betty','Boop')
Database B:
create table H (e int
primary key, k char, m int)
insert into H values
(1,'Cleaner',12500), (2,'Manager',31400)
[create view W of (e
int, f char, g char) as get'http://localhost:8180/A/A/D']
create view V as select * from W natural join H
The square brackets here are added because of the embedded newline added in the formatting of the page.
After setting up the databases on A and B with B’s views defined, we see the transaction log contents for A and B. Some of the numbers shown will be used in RVV and ETags in what follows.



We see at position 381 that the URL http://localhost:8180/A/A/D has been provided in metadata for the view W. W was defined in position 366 in terms of the anonymous structure with columns E, F, G declared at position 290.
The use of position numbers instead of identifiers in the
definition of view V at position 439 is a standard feature of Pyrrho to allow
renaming of objects.
In the blog post we now have the following operations on
database B:
select e,f,m,check
from V where e=1

Note that in normal use there is no need to request the
check pseudocolumn: it is here so can show what is happening within the two
databases. The database API uses it to implement the Versioned feature in
client side “database model” classes.
Here, the check value was requested explicitly in the SELECT
statement, and shows that this row of the join uses a row from A with defining
position 209 placed there in transaction 193 (see the log for A) and a row from
B with defining position 208 arising from transaction 192 (see the log for B).
The debug information for server A shows the REST request from B to
A, and the ETag it constructed.
The ETag consists of an RVV for the first row of the result
(mentioned above), and a readCheck for the read operation carried out by A.
This was a specific row in table D (position 69) with key (1) .
The next operation is
update v set
f='Elizabeth' where e=2
We see there is now an updated ETag supplied by A showing
the new transaction that has updated the record defined at 241.
Also check B’s view using the join:
The next operation is an Insert into the View/RestView/Join
combination:
[insert into
v(e,f,g,k,m)
values(3,'Fred','Smith','Janitor',22160)]
This time the readCheck information indicates it will conflict with any read operation on table 69.
And again verifying the view from B:
Finally, we try a deletion from the View/RestView/Join
combination:
Subscribe to:
Posts (Atom)

